14 KiB
KIMI AI Free Service




Supports high-speed streaming output, multi-turn dialogues, internet search, long document reading, image analysis, zero-configuration deployment, multi-token support, and automatic session trace cleanup.
Fully compatible with the ChatGPT interface.
Also, the following four free APIs are available for your attention:
Step to the Stars (StepChat) API to API step-free-api
Ali Tongyi (Qwen) API to API qwen-free-api
ZhipuAI (Wisdom Map Clear Words) API to API glm-free-api
Listening Intelligence (Emohaa) API to API emohaa-free-api
Table of Contents
- Disclaimer
- Online Experience
- Effect Examples
- Access Preparation
- Docker Deployment
- Native Deployment
- API List
- Precautions
Disclaimer
This organization and individuals do not accept any financial donations and transactions. This project is purely for research, communication, and learning purposes!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
Online Experience
This link is only for temporary testing of functions and cannot be used for a long time. For long-term use, please deploy by yourself.
https://udify.app/chat/Po0F6BMJ15q5vu2P
Effect Examples
Identity Verification

Multi-turn Dialogue
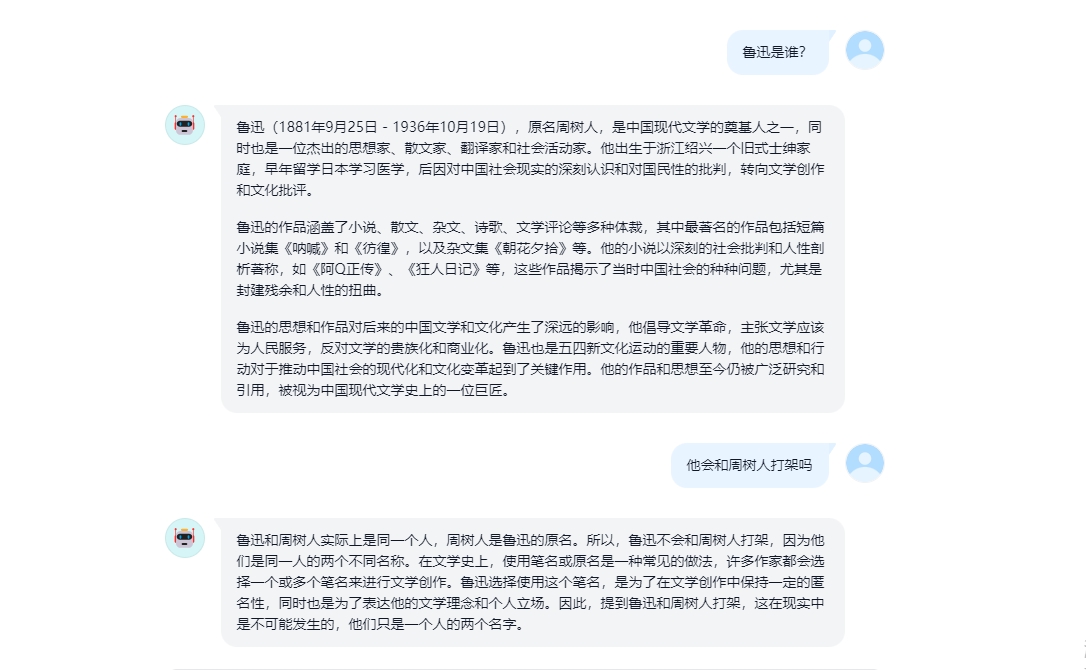
Internet Search
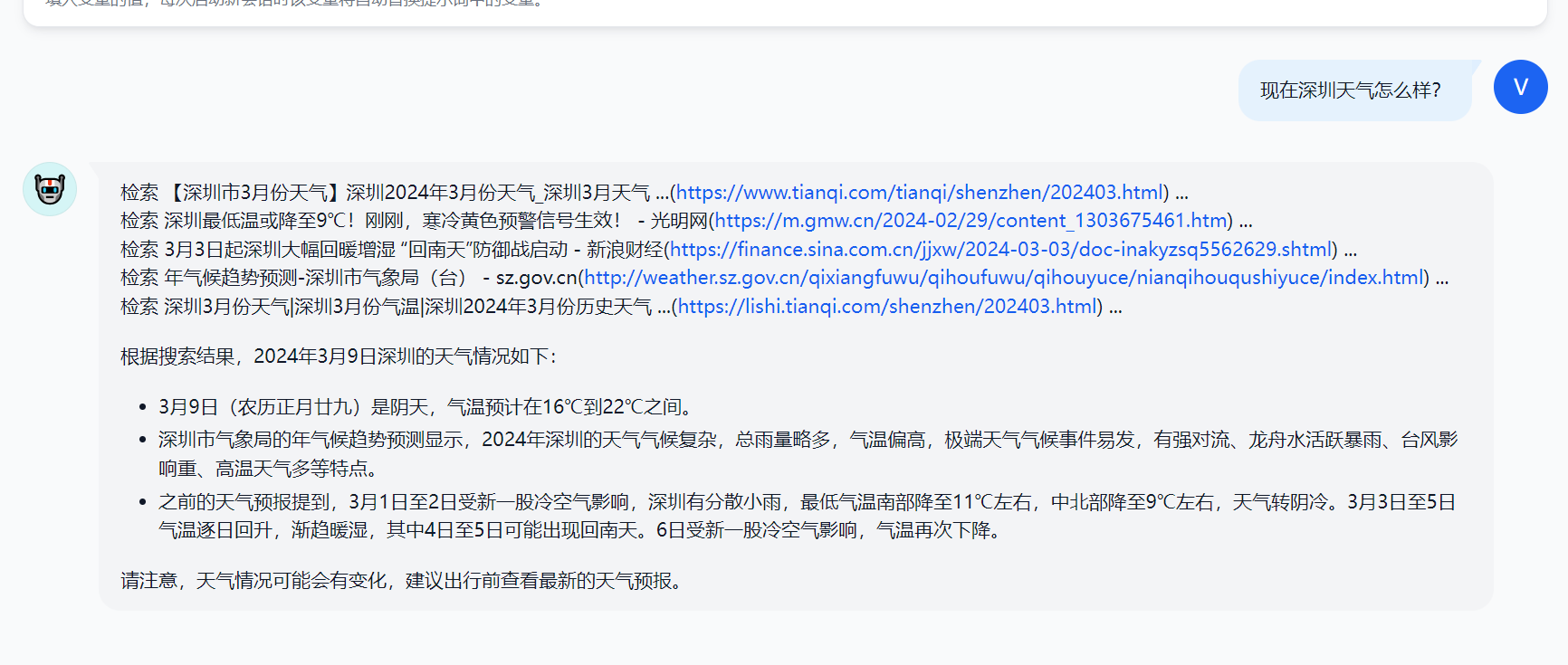
Long Document Reading

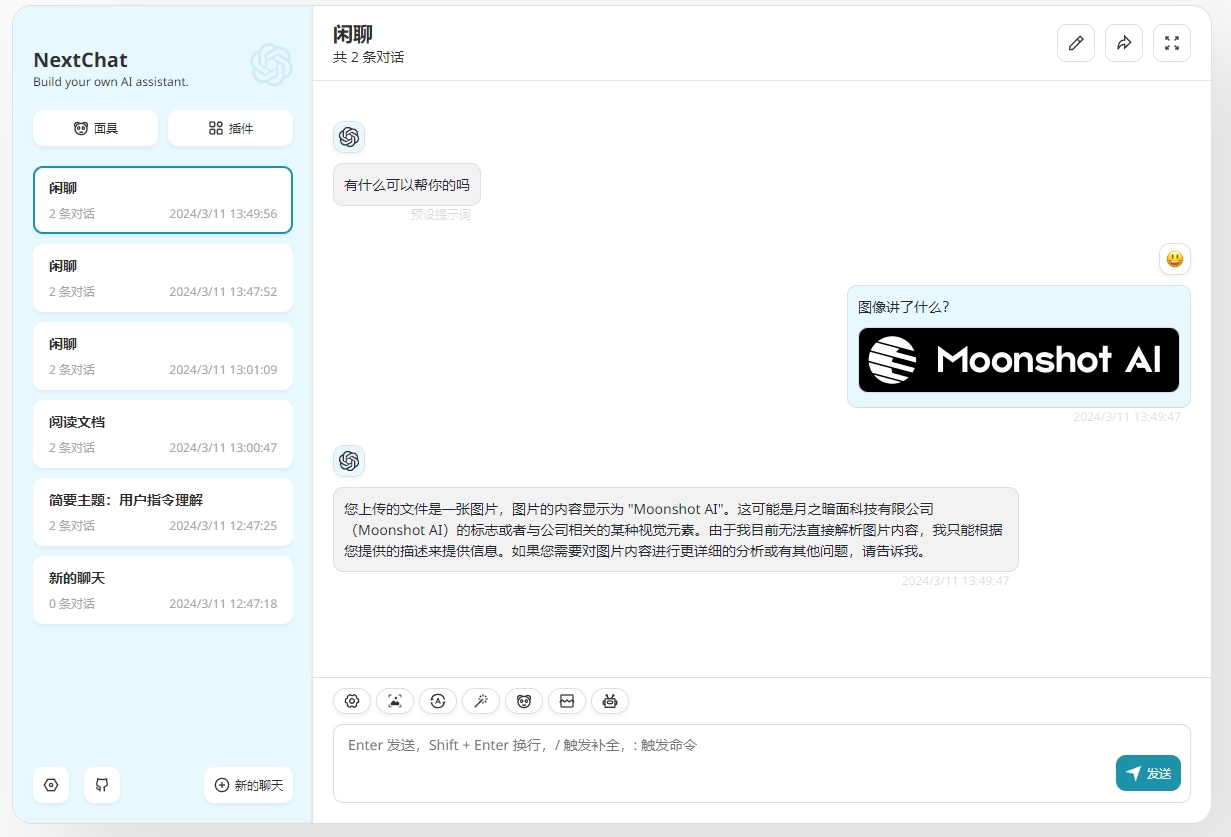
Image Analysis
Consistent Responsiveness
Access Preparation
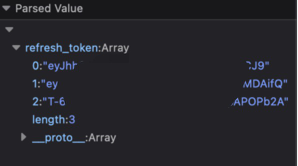
Get the refresh_token from kimi.moonshot.cn
Start a conversation with kimi at will, then open the developer tool with F12, and find the value of refresh_token from Application > Local Storage, which will be used as the value of the Bearer Token in Authorization: Authorization: Bearer TOKEN

If you see refresh_token as an array, please use . to join it before using.
Multi-Account Access
Currently, kimi limits ordinary accounts to only 30 rounds of long-text Q&A within every 3 hours (short text is unlimited). You can provide multiple account refresh_tokens and use , to join them:
Authorization: Bearer TOKEN1,TOKEN2,TOKEN3
The service will pick one each time a request is made.
Docker Deployment
Please prepare a server with a public IP and open port 8000.
Pull the image and start the service
docker run -it -d --init --name kimi-free-api -p 8000:8000 -e TZ=Asia/Shanghai vinlic/kimi-free-api:latest
check real-time service logs
docker logs -f kimi-free-api
Restart service
docker restart kimi-free-api
Out of service
docker stop kimi-free-api
Docker-compose deployment
version: '3'
services:
kimi-free-api:
container_name: kimi-free-api
image: vinlic/kimi-free-api:latest
restart: always
ports:
- "8000:8000"
environment:
- TZ=Asia/Shanghai
Native deployment
Please prepare a server with a public IP and open port 8000.
Please install the Node.js environment and configure the environment variables first, and confirm that the node command is available.
Install dependencies
npm i
Install PM2 for process guarding
npm i -g pm2
Compile and build. When you see the dist directory, the build is complete.
npm run build
Start service
pm2 start dist/index.js --name "kimi-free-api"
View real-time service logs
pm2 logs kimi-free-api
Restart service
pm2 reload kimi-free-api
Out of service
pm2 stop kimi-free-api
interface list
Currently, the /v1/chat/completions interface compatible with openai is supported. You can use the client access interface compatible with openai or other clients, or use online services such as dify Access and use.
Conversation completion
Conversation completion interface, compatible with openai's chat-completions-api.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [refresh_token]
Request data:
{
// Fill in the model name as you like. If you do not want to output the retrieval process model name, please include silent_search.
"model": "kimi",
"messages": [
{
"role": "user",
"content": "test"
}
],
// Whether to enable online search, default false
"use_search": true,
// If using SSE stream, please set it to true, the default is false
"stream": false
}
Response data:
{
"id": "cnndivilnl96vah411dg",
"model": "kimi",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! I am Kimi, an artificial intelligence assistant developed by Dark Side of the Moon Technology Co., Ltd. I am good at conversation in Chinese and English. I can help you obtain information, answer questions, and read and understand the documents you provide. and web content. If you have any questions or need help, feel free to let me know!"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 1710152062
}
Document interpretation
Provide an accessible file URL or BASE64_URL to parse.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [refresh_token]
Request data:
{
// Fill in the model name as you like. If you do not want to output the retrieval process model name, please include silent_search.
"model": "kimi",
"messages": [
{
"role": "user",
"content": [
{
"type": "file",
"file_url": {
"url": "https://mj101-1317487292.cos.ap-shanghai.myqcloud.com/ai/test.pdf"
}
},
{
"type": "text",
"text": "What does the document say?"
}
]
}
],
// It is recommended to turn off online search to prevent interference in interpreting results.
"use_search": false
}
Response data:
{
"id": "cnmuo7mcp7f9hjcmihn0",
"model": "kimi",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The document contains several examples of ancient magical spells from magical texts from the ancient Greek and Roman periods known as PGM (Papyri Graecae Magicae). The following are examples of several spells mentioned in the document Contents:\n\n1. The first spell (PMG 4.1390 – 1495) describes a ritual that requires leaving some of your leftover bread, dividing it into seven small pieces, and then going to the heroes, gladiators, and those who died violent deaths The place where people were killed. Spell a spell on the piece of bread and throw it out, then pick up some contaminated soil from the ritual site and throw it into the home of the woman you like, then go to sleep. The content of the spell is to pray to the goddess of fate (Moirai), The Roman goddesses of Fates and the forces of nature (Daemons) were invoked to help make wishes come true.\n\n2. The second incantation (PMG 4.1342 – 57) was a summoning spell performed by speaking a series of mystical names and Words to summon a being called Daemon to cause a person named Tereous (born from Apia) to be mentally and emotionally tortured until she came to the spellcaster Didymos (born from Taipiam).\n \n3. The third spell (PGM 4.1265 – 74) mentions a mysterious name called NEPHERIĒRI, which is related to Aphrodite, the goddess of love. In order to win the heart of a beautiful woman, one needs to keep it for three days of purity, offer frankincense and recite the name while offering the offering. Then, as you approach the lady, recite the name silently seven times in your mind and do this for seven consecutive days with the hope of success.\n\n4. The fourth mantra ( PGM 4.1496 – 1) describes an incantation recited while burning myrrh. This incantation is a prayer to myrrh in the hope that it will attract a person named [name ] woman (her mother's name was [name]), making her unable to sit, eat, look at or kiss other people, but instead had only the caster in her mind until she came to the caster.\n\nThese Spells reflect ancient people's beliefs in magic and supernatural powers, and the ways in which they attempted to influence the emotions and behavior of others through these spells."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 100920
}
Image analysis
Provide an accessible image URL or BASE64_URL to parse.
This format is compatible with the gpt-4-vision-preview API format. You can also use this format to transmit documents for parsing.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [refresh_token]
Request data:
{
// Fill in the model name as you like. If you do not want to output the retrieval process model name, please include silent_search.
"model": "kimi",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://www.moonshot.cn/assets/logo/normal-dark.png"
}
},
{
"type": "text",
"text": "What does the image describe?"
}
]
}
],
// It is recommended to turn off online search to prevent interference in interpreting results.
"use_search": false
}
Response data:
{
"id": "cnn6l8ilnl92l36tu8ag",
"model": "kimi",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The image shows the words "Moonshot AI", which may be the logo or brand identity of Dark Side of the Moon Technology Co., Ltd. (Moonshot AI). Usually such images are used to represent a company or product and convey brand information .Since the image is in PNG format, it could be a logo with a transparent background, used on a website, app, or other visual material."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 1710123627
}
Precautions
Nginx anti-generation optimization
If you are using Nginx reverse proxy kimi-free-api, please add the following configuration items to optimize the output effect of the stream and optimize the experience.
# Turn off proxy buffering. When set to off, Nginx will immediately send client requests to the backend server and immediately send responses received from the backend server back to the client.
proxy_buffering off;
# Enable chunked transfer encoding. Chunked transfer encoding allows servers to send data in chunks for dynamically generated content without knowing the size of the content in advance.
chunked_transfer_encoding on;
# Turn on TCP_NOPUSH, which tells Nginx to send as much data as possible before sending the packet to the client. This is usually used in conjunction with sendfile to improve network efficiency.
tcp_nopush on;
# Turn on TCP_NODELAY, which tells Nginx not to delay sending data and to send small data packets immediately. In some cases, this can reduce network latency.
tcp_nodelay on;
#Set the timeout to keep the connection, here it is set to 120 seconds. If there is no further communication between client and server during this time, the connection will be closed.
keepalive_timeout 120;
Token statistics
Since the inference side is not in kimi-free-api, the token cannot be counted and will be returned as a fixed number!!!!!
Star History
[](https://star-history.com/ #LLM-Red-Team/kimi-free-api&Date)