Qwen AI Free Service




Supports high-speed streaming output, multi-turn dialogues, internet search, long document reading, image analysis, zero-configuration deployment, multi-token support, and automatic session trace cleanup.
Fully compatible with the ChatGPT interface.
Also, the following free APIs are available for your attention:
Moonshot AI (Kimi.ai) API to API kimi-free-api
StepFun (StepChat) API to API step-free-api
ZhipuAI (ChatGLM) API to API glm-free-api
Meta Sota (metaso) API to API metaso-free-api
Iflytek Spark (Spark) API to API spark-free-api
Lingxin Intelligence (Emohaa) API to API emohaa-free-api (OUT OF ORDER)
目录
- Announcement
- Online experience
- Effect Examples
- Access preparation
- Docker Deployment
- Native Deployment
- Recommended Clients
- Interface List
- Notification
- Star History
Announcement
This API is unstable. So we highly recommend you go to the Ali use the offical API, avoiding banned.
This organization and individuals do not accept any financial donations and transactions. This project is purely for research, communication, and learning purposes!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
For personal use only, it is forbidden to provide services or commercial use externally to avoid causing service pressure on the official, otherwise, bear the risk yourself!
Online experience
This link is only for temporary testing of functions and cannot be used for a long time. For long-term use, please deploy by yourself.
https://udify.app/chat/qOXzVl5kkvhQXM8r
Effect Examples
Identity Verification
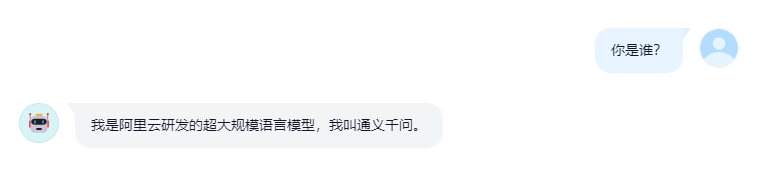
Multi-turn Dialogue
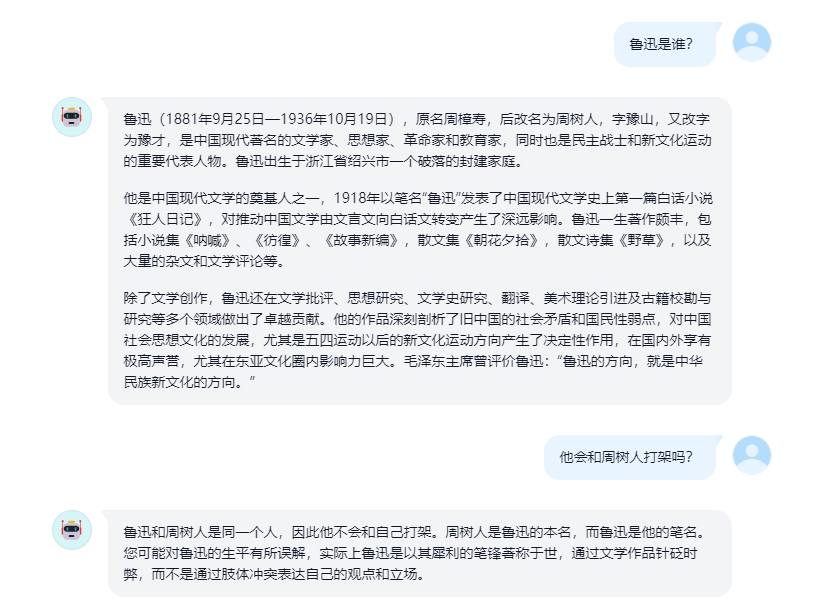
AI Drawing
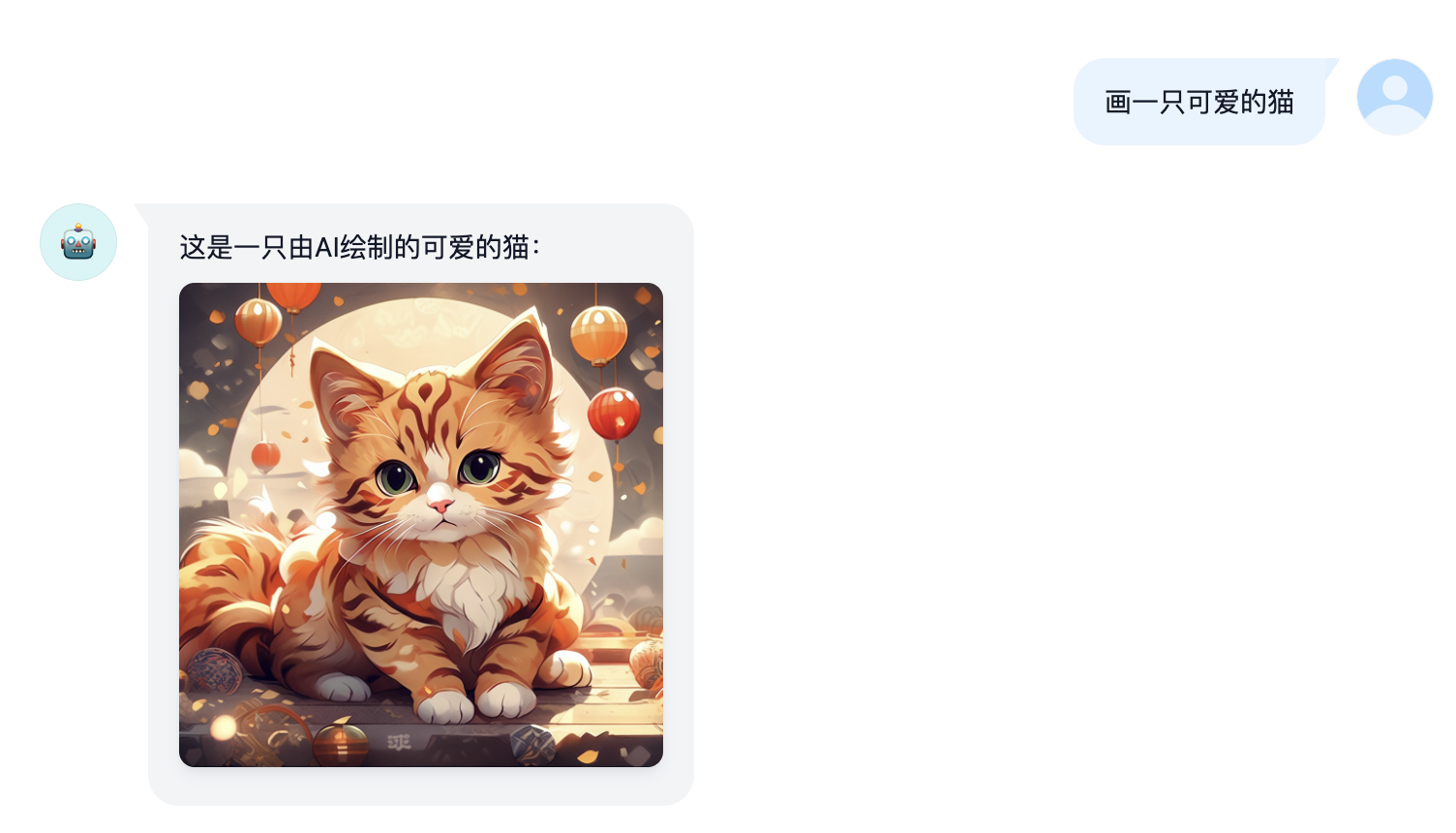
Long Document Reading

Image Analysis

10-Thread Concurrency Test

Access Preparation
Method1
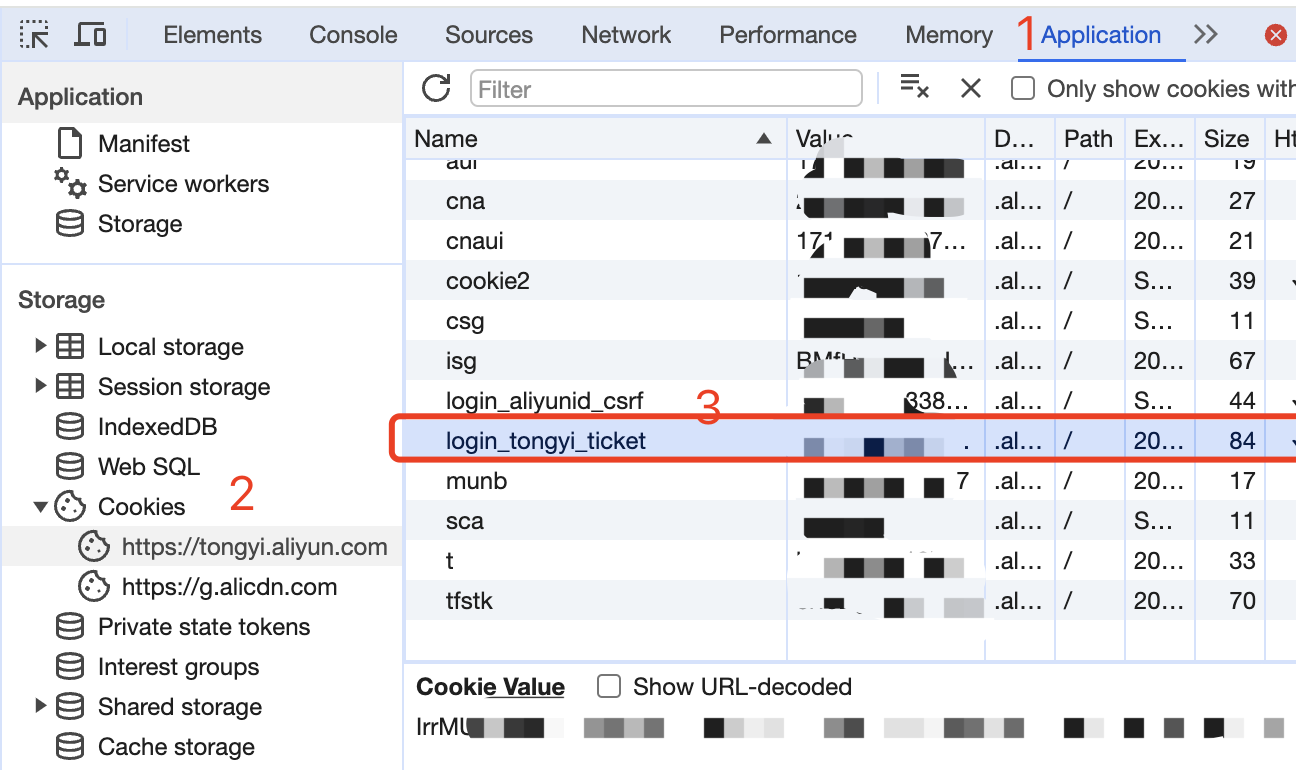
Log in to Tongyi Qianwen
Enter Tongyi Qianwen and start a random conversation, then press F12 to open the developer tools. Find the value of tongyi_sso_ticket in Application > Cookies, which will be used as the Bearer Token value for Authorization: Authorization: Bearer TOKEN
Method2
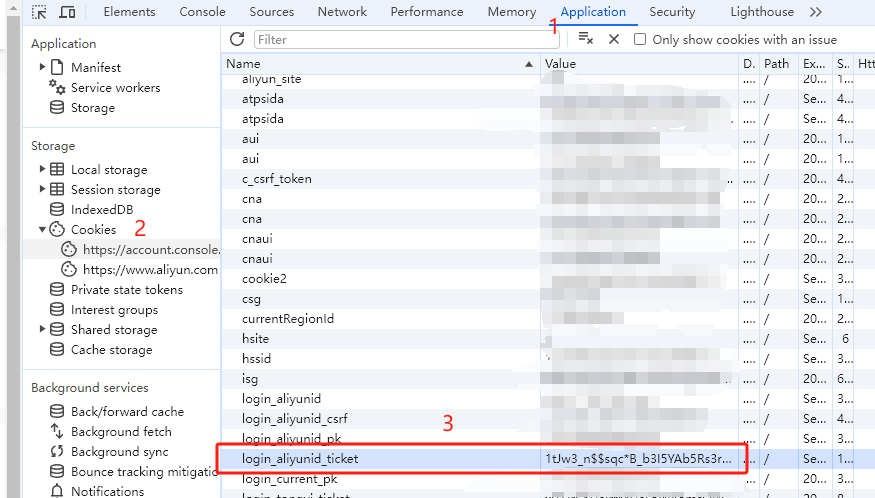
Log in to Alibaba Cloud (not recommended if the account has important assets such as servers). If the account has not previously entered Tongyi Qianwen, you need to first agree to the terms, otherwise it will not take effect.
Then press F12 to open the developer tools. Find the value of login_aliyunid_ticket in Application > Cookies, which will be used as the Bearer Token value for Authorization: Authorization: Bearer TOKEN
Multi-Account Access
You can provide multiple account tongyi_sso_ticket or login_aliyunid_ticket and use , to join them:
Authorization: Bearer TOKEN1,TOKEN2,TOKEN3
The service will pick one each time a request is made.
Docker Deployment
Please prepare a server with a public IP and open port 8000.
Pull the image and start the service
docker run -it -d --init --name qwen-free-api -p 8000:8000 -e TZ=Asia/Shanghai vinlic/qwen-free-api:latest
check real-time service logs
docker logs -f step-free-api
Restart service
docker restart step-free-api
Shut down service
docker stop step-free-api
Docker-compose Deployment
version: '3'
services:
qwen-free-api:
container_name: qwen-free-api
image: vinlic/qwen-free-api:latest
restart: always
ports:
- "8000:8000"
environment:
- TZ=Asia/Shanghai
Render Deployment
Attention: Some deployment regions may not be able to connect to Kimi. If container logs show request timeouts or connection failures (Singapore has been tested and found unavailable), please switch to another deployment region!
Attention: Container instances for free accounts will automatically stop after a period of inactivity, which may result in a 50-second or longer delay during the next request. It is recommended to check Render Container Keepalive
-
Fork this project to your GitHub account.
-
Visit Render and log in with your GitHub account.
-
Build your Web Service (
New+->Build and deploy from a Git repository->Connect your forked project->Select deployment region->Choose instance type as Free->Create Web Service). -
After the build is complete, copy the assigned domain and append the URL to access it.
Vercel Deployment
Note: Vercel free accounts have a request response timeout of 10 seconds, but interface responses are usually longer, which may result in a 504 timeout error from Vercel!
Please ensure that Node.js environment is installed first.
npm i -g vercel --registry http://registry.npmmirror.com
vercel login
git clone https://github.com/LLM-Red-Team/qwen-free-api
cd qwen-free-api
vercel --prod
Native Deployment
Please prepare a server with a public IP and open port 8000.
Please install the Node.js environment and configure the environment variables first, and confirm that the node command is available.
Install dependencies
npm i
Install PM2 for process guarding
npm i -g pm2
Compile and build. When you see the dist directory, the build is complete.
npm run build
Start service
pm2 start dist/index.js --name "qwen-free-api"
View real-time service logs
pm2 logs qwen-free-api
Restart service
pm2 reload qwen-free-api
Shut down service
pm2 stop qwen-free-api
Recommended Clients
Using the following second-developed clients for free-api series projects is faster and easier, and supports document/image uploads!
Clivia's modified LobeChat https://github.com/Yanyutin753/lobe-chat
Time@'s modified ChatGPT Web https://github.com/SuYxh/chatgpt-web-sea
interface list
Currently, the /v1/chat/completions interface compatible with openai is supported. You can use the client access interface compatible with openai or other clients, or use online services such as dify Access and use.
Conversation completion
Conversation completion interface, compatible with openai's chat-completions-api.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [tongyi_sso_ticket/login_aliyunid_ticket]
Request data:
{
// Fill in the model name as you like.
"model": "qwen",
// Currently, multi-round conversations are realized based on message merging, which in some scenarios may lead to capacity degradation and is limited by the maximum number of tokens in a single round.
// If you want a native multi-round dialog experience, you can pass in the ids obtained from the last round of messages to pick up the context
// "conversation_id": "bc9ef150d0e44794ab624df958292300-40811965812e4782bb87f1a9e4e2b2cd",
"messages": [
{
"role": "user",
"content": "who RU?"
}
],
// If using SSE stream, please set it to true, the default is false
"stream": false
}
Response data:
{
// For a native multi-round conversation experience, this id, you can pass in the conversation_id for the next round of conversation to pick up the context
"id": "bc9ef150d0e44794ab624df958292300-40811965812e4782bb87f1a9e4e2b2cd",
"model": "qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "I'm Qwen."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 1710152062
}
AI Drawing
Conversation completion interface, compatible with openai's chat-completions-api.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [tongyi_sso_ticket/login_aliyunid_ticket]
Request data:
{
// 可以乱填
"model": "wanxiang",
"prompt": "A cut cat"
}
Response data:
{
"created": 1711507734,
"data": [
{
"url": "https://wanx.alicdn.com/wanx/1111111111/text_to_image/7248e85cfda6491aae59c54e7e679b17_0.png"
}
]
}
Document interpretation
Provide an accessible file URL or BASE64_URL to parse.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [refresh_token]
Request data:
{
"model": "qwen",
"messages": [
{
"role": "user",
"content": [
{
"type": "file",
"file_url": {
"url": "https://mj101-1317487292.cos.ap-shanghai.myqcloud.com/ai/test.pdf"
}
},
{
"type": "text",
"text": "What does the document say?"
}
]
}
]
}
Response data:
{
"id": "b56ea6c9e86140429fa2de6a6ec028ff",
"model": "qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "This is a doc about the magic of love. balabala..."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 1712253736
}
Image analysis
Provide an accessible image URL or BASE64_URL to parse.
This format is compatible with the gpt-4-vision-preview API format. You can also use this format to transmit documents for parsing.
POST /v1/chat/completions
The header needs to set the Authorization header:
Authorization: Bearer [refresh_token]
请求数据:
{
"model": "qwen",
"messages": [
{
"role": "user",
"content": [
{
"type": "file",
"file_url": {
"url": "https://img.alicdn.com/imgextra/i1/O1CN01CC9kic1ig1r4sAY5d_!!6000000004441-2-tps-880-210.png"
}
},
{
"type": "text",
"text": "What does the image describe?"
}
]
}
]
}
Response data:
{
"id": "895fbe7fa22442d499ba67bb5213e842",
"model": "qwen",
"object": "chat.completion",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "It's the logo of Qwen."
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 1,
"completion_tokens": 1,
"total_tokens": 2
},
"created": 1712254066
}
refresh_token survival detection
Check whether refresh_token is alive. If live is not true, otherwise it is false. Please do not call this interface frequently (less than 10 minutes).
POST /token/check
Request data:
{
"token": "QIhaHrrXUaIrWMUmL..."
}
Response data:
{
"live": true
}
Notification
Nginx anti-generation optimization
If you are using Nginx reverse proxy qwen-free-api, please add the following configuration items to optimize the output effect of the stream and optimize the experience.
# Turn off proxy buffering. When set to off, Nginx will immediately send client requests to the backend server and immediately send responses received from the backend server back to the client.
proxy_buffering off;
# Enable chunked transfer encoding. Chunked transfer encoding allows servers to send data in chunks for dynamically generated content without knowing the size of the content in advance.
chunked_transfer_encoding on;
# Turn on TCP_NOPUSH, which tells Nginx to send as much data as possible before sending the packet to the client. This is usually used in conjunction with sendfile to improve network efficiency.
tcp_nopush on;
# Turn on TCP_NODELAY, which tells Nginx not to delay sending data and to send small data packets immediately. In some cases, this can reduce network latency.
tcp_nodelay on;
#Set the timeout to keep the connection, here it is set to 120 seconds. If there is no further communication between client and server during this time, the connection will be closed.
keepalive_timeout 120;
Token statistics
Since the inference side is not in qwen-free-api, the token cannot be counted and will be returned as a fixed number!!!!!